- Information
- AI Chat
Data mining exam questions
Question Bank for Data Mining Course
Course
Data Mining
91 Documents
Students shared 91 documents in this course
University
Assiut University
Academic year: 2023/2024
Listed bookData Mining: Concepts and Techniques
Uploaded by:

531Uploads
415upvotes

Preview text
1. Data mining is best described as the process of
a. identifying patterns in data.
b. deducing relationships in data.
c. representing data.
d. simulating trends in data.
2. Data used to build a data mining model.
a. validation data
b. training data
c. test data
d. hidden data
3. Supervised learning and unsupervised clustering both require at least one
a. hidden attribute.
b. output attribute.
c. input attribute.
d. categorical attribute.
4. Supervised learning differs from unsupervised clustering in that supervised learning
requires
a. at least one input attribute.
b. input attributes to be categorical.
c. at least one output attribute.
d. ouput attriubutes to be categorical.
5. Which of the following is a valid production rule for the decision tree below?
a. IF Business Appointment = No & Temp above 70 = No
THEN Decision = wear slacks
b. IF Business Appointment = Yes & Temp above 70 = Yes
THEN Decision = wear shorts
c. IF Temp above 70 = No
THEN Decision = wear shorts
Business
Appoint-
ment?
Temp
above
70?
No
Yes
Decision =
wear jeans
No
Yes
Decision =
wear slacks
Decision =
wear shorts
d. IF Business Appointment= No & Temp above 70 = No
THEN Decision = wear jeans
6. A statement to be tested.
a. theory
b. procedure
c. principle
d. hypothesis
7. Which statement about outliers is true?
a. Outliers should be identified and removed from a dataset.
b. Outliers should be part of the training dataset but should not be present in the test data.
c. Outliers should be part of the test dataset but should not be present in the training data.
d. The nature of the problem determines how outliers are used.
e. More than one of a,b,c or d is true.
8. Assume that we have a dataset containing information about 200 individuals. One
hundred of these individuals have purchased life insurance. A supervised data mining
session has discovered the following rule:
IF age < 30 & credit card insurance = yes
THEN life insurance = yes
Rule Accuracy: 70%
Rule Coverage: 63%
How many individuals in the class life insurance= no have credit card insurance and are less
than 30 years old?
a. 63
b. 70
c. 30
d. 27
9. unlike traditional production rules, association rules
a. allow the same variable to be an input attribute in one rule and an output attribute
in another rule.
b. allow more than one input attribute in a single rule.
c. require input attributes to take on numeric values.
d. require each rule to have exactly one categorical output attribute.
10. Given a rule of the form IF X THEN Y, rule confidence is defined as the conditional
probability that
a. Y is true when X is known to be true.
b. X is true when Y is known to be true.
c. Y is false when X is known to be false.
d. X is false when Y is known to be false.
11. Association rule support is defined as
a. the percentage of instances that contain the antecendent conditional items listed in the
association rule.
a. Mean
b. Median
c. Mode
d. Range
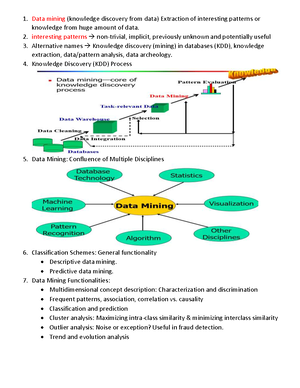
19. ................... is an essential process where intelligent methods are applied to extract data patterns.
A) Data warehousing
B) Data mining
C) Text mining
D) Data selection
20. Which of the following is not a data mining functionality?
A) Characterization and Discrimination
B) Classification and regression
C) Selection and interpretation
D) Clustering and Analysis
21. The various aspects of data mining methodologies is/are ...................
i) Mining various and new kinds of knowledge
ii) Mining knowledge in multidimensional space
iii) Pattern evaluation and pattern or constraint-guided mining.
iv) Handling uncertainty, noise, or incompleteness of data
A) i, ii and iv only
B) ii, iii and iv only
C) i, ii and iii only
D) All i, ii, iii and iv
22. Task of inferring a model from labeled training data is called
A. Unsupervised learning
B. Supervised learning
C. Reinforcement learning
23. Discriminating between spam and ham e-mails is a classification task, true or
false?
A. True B. False
24. Which of the following is true for Classification?
a) A subdivision of a set
b) A measure of the accuracy
c) The task of assigning a classification
d) All of these
25. Data mining is?
a) time variant non-volatile collection of data
b) The actual discovery phase of a knowledge
c) The stage of selecting the right data
d) None of these
26. Which of the following is general characteristics or features of a target class of
data?
a) Data selection
b) Data discrimination
c) Data Classification
d) Data Characterization
27. What is noise?
a) component of a network
theory
C. The task of assigning a classification to a set of examples
D. None of these
32. Binary attribute are
A. This takes only two values. In general, these values will be 0 and 1 and .they can
be coded as one bit
B. The natural environment of a certain species
C. Systems that can be used without knowledge of internal operations
D. None of these
33. Classification accuracy is
A. A subdivision of a set of examples into a number of classes
B. Measure of the accuracy, of the classification of a concept that is given by a
certain theory
C. The task of assigning a classification to a set of examples
D. None of these
34. Cluster is
A. Group of similar objects that differ significantly from other objects
B. Operations on a database to transform or simplify data in order to prepare it for a
machine-learning algorithm
C. Symbolic representation of facts or ideas from which information can potentially be
extracted
D. None of these
35. Data selection is
A. The actual discovery phase of a knowledge discovery process
B. The stage of selecting the right data for a KDD process
C. A subject-oriented integrated time variant non-volatile collection of data in support of
management
D. None of these
36. Discovery is
A. It is hidden within a database and can only be recovered if one is given certain clues
(an example IS encrypted information).
B. The process of executing implicit previously unknown and potentially useful
information from data
C. An extremely complex molecule that occurs in human chromosomes and that carries
genetic information in the form of genes.
D. None of these
37. KDD (Knowledge Discovery in Databases) is referred to
A.
Non-trivial extraction of implicit previously unknown and potentially useful information
from data
B. Set of columns in a database table that can be used to identify each record within this table
uniquely.
C. collection of interesting and useful patterns in a database
D. none of these
A. 3
B. 6
C. 48
D. 72
43. Which of the following statements about Naive Bayes is incorrect?
A. Attributes are equally important.
B. Attributes are statistically dependent of one another given the class value.
C. Attributes are statistically independent of one another given the class value.
D. All of the above
49. In association rule mining the
generation of the frequent itermsets is the computational
intensive step
a b. False
1. Data Characterization is a summarization of the general characteristics or features
of a target class of data.
A) True
B) False
2. Data selection is a comparison of the general features of the target class data
objects against the general features of objects from one or multiple contrasting
classes.
A. True
B. False
50. The problem of finding hidden structure in unlabeled data is called
A. Supervised learning
B. Unsupervised learning
C. Reinforcement learning
51. The choice of a data mining tool is made at this step of the KDD
process.
a. goal identification
b. creating a target dataset
c. data preprocessing
d. data mining
52. Attibutes may be eliminated from the target dataset during this step of
the KDD process.
a. creating a target dataset
b. data preprocessing
c. data transformation
d. data mining
53. A common method used by some data mining techniques to deal
with missing data items during the learning process.
a) replace missing real-valued data items with class means
b) discard records with missing data
c) replace missing attribute values with the values found within
other similar instances
d) ignore missing attribute values
54. The term data mining was originally used to ______.
a. include most forms of data analysis in order to increase sales
b. describe the prices through which previously unknown patterns
in data were discovered
c. describe the analysis of huge datasets stored in data
warehouses
d. All of the above
55. What is a major characteristic of data mining?
a. Because of the large amounts of data and massive search
efforts, it is sometimes necessary to use serial processing for
data mining
View Answer
Ans : C
Explanation: Mining of Correlations : It is a kind of additional analysis performed to
uncover interesting statistical correlations between associated-attribute-value pairs or
between two item sets to analyze that if they have positive, negative or no effect on each
other.
59. __________ may be defined as the data objects that do not comply with the
general behavior or model of the data available.
A. Outlier Analysis
B. Evolution Analysis
C. Prediction
D. Classification
View Answer
Ans : A
Explanation: Outlier Analysis : Outliers may be defined as the data objects that do not
comply with the general behavior or model of the data available.
60. "Efficiency and scalability of data mining algorithms" issues comes under?
A. Mining Methodology and User Interaction Issues
B. Performance Issues
C. Diverse Data Types Issues
D. None of the above
View Answer
Ans : B
Explanation: In order to effectively extract the information from huge amount of data in
databases, data mining algorithm must be efficient and scalable.
61. What is the use of data cleaning?
A. to remove the noisy data
B. correct the inconsistencies in data
C. transformations to correct the wrong data.
D. All of the above
View Answer
Ans : D
Explanation: Data cleaning is a technique that is applied to remove the noisy data and
correct the inconsistencies in data. Data cleaning involves transformations to correct the
wrong data. Data cleaning is performed as a data preprocessing step while preparing the
data for a data warehouse.
62. Data Mining System Classification consists of?
A. Database Technology
B. Machine Learning
C. computer Vision
D. All of the above
View Answer
Ans : D
Explanation: A data mining system can be classified according to the following criteria :
Database Technology, Statistics, Machine Learning, Information Science, Visualization,
Other Disciplines
63. Which of the following is correct application of data mining?
A. Market Analysis and Management
B. Corporate Analysis & Risk Management
C. Fraud Detection
D. All of the above
View Answer
Ans : D
Explanation: Data mining is highly useful in the following domains : Market Analysis and
Management, Corporate Analysis & Risk Management, Fraud Detection
67. The first steps involved in the knowledge discovery is?
A. Data Integration
B. Data Selection
C. Data Transformation
D. Data Cleaning
View Answer
Ans : D
Explanation: The first steps involved in the knowledge discovery is Data Integration.
68. In which step of Knowledge Discovery, multiple data sources are combined?
A. Data Cleaning
B. Data Integration
C. Data Selection
D. Data Transformation
View Answer
Ans : B
69. The most commonly used algorithm to discover association rules by recursively
identifying frequent item sets
a. A priori algorithm
b. Ordinal data
c. Nominal data
d. Categorical data
70. A process that uses statistical, mathematical, artificial intelligence, and machine-
learning techniques to extract and identify useful information and subsequent
knowledge from large databases.
a. RapidMiner
b. Gini index
c. Sequence mining
d. Data mining
71. A machine learning process that performs rule induction or a related procedure to
establish knowledge from large databases
a. Categorical data
b. K fold cross validation
c. Numeric data
d. Knowledge discovery in databases
72. Commonly co-occurring groupings of things. AKA market-basket analysis.
a. Associations
b. Ratio data
c. Prediction
d. Classification
73. A type of data that represents the numeric values of specific variables. for
example age number of children etc
a. Ratio data
b. Numeric data
c. Nominal data
d. Interval data
78. Supervised induction used to analyze the historical data stored in a database and
to automatically generate a model that can predict future behavior
a. Classification
b. Associations
c. Clustering
d. Prediction
79. The number of iterations in apriori ___________ Select one:
a. increases with the size of the data
b. decreases with the increase in size of the data
c. increases with the size of the maximum frequent set
d. decreases with increase in size of the maximum frequent set
c: increases with the size of the maximum frequent set
80. To determine association rules from frequent item sets Select one:
a. Only minimum confidence needed
b. Neither support not confidence needed
c. Both minimum support and confidence are needed
d. Minimum support is needed
Feedback: Both minimum support and confidence are needed
81. If {A,B,C,D} is a frequent itemset, candidate rules which is not possible is Select one:
a. C – > A
b. D – >ABCD
c. A – > BC d.
B – > ADC
82. Feedback: D – >ABCD
86. Noise is a random error or variance in measured variables.
Ans: Noise
83. ______ routines attempt to fill in missing values, smooth out noise while
identifying outlines, and correct inconsistencies in the data.
Ans: Data cleaning
84. ________ is used to refer to systems and technologies that provide the business
with the means for decision-makers to extract personalized meaningful
information about their business and industry.
Ans: Business Intelligence
85. In Smoothing by bin means each value in a bin is replaced by the mean value of
the bin.
Ans: Smoothing by bin means
86. ______ regression involves finding the “best” line to fit two variables so that
one variable can be used to predict the other.
Ans: Linear
87. _____ works to remove the noise from the data that includes techniques like
binning, clustering, and regression.
Ans: Smoothing
88. Redundancies can be detected by correlation analysis. (True/False)
Ans: True
89. The ______ technique uses encoding mechanisms to reduce the data set size.
Ans: Data compression
90. In which Strategy of data reduction redundant attributes are detected.
A. Date cube aggregation
B. Numerosity reduction
C. Data compression
D. Dimension reduction
Ans: D. Dimension reduction
91. The _____ rule can be used to segment numeric data into relatively uniform,
“natural” intervals.
Ans: 3-4-
92. Oracle, SQL/Server, DB2 are examples for _____________.
Ans: DBMS
Was this document helpful?
Data mining exam questions
Course: Data Mining
91 Documents
Students shared 91 documents in this course
University: Assiut University
Was this document helpful?

1
1. Data mining is best described as the process of
a. identifying patterns in data.
b. deducing relationships in data.
c. representing data.
d. simulating trends in data.
2. Data used to build a data mining model.
a. validation data
b. training data
c. test data
d. hidden data
3. Supervised learning and unsupervised clustering both require at least one
a. hidden attribute.
b. output attribute.
c. input attribute.
d. categorical attribute.
4. Supervised learning differs from unsupervised clustering in that supervised learning
requires
a. at least one input attribute.
b. input attributes to be categorical.
c. at least one output attribute.
d. ouput attriubutes to be categorical.
5. Which of the following is a valid production rule for the decision tree below?
a. IF Business Appointment = No & Temp above 70 = No
THEN Decision = wear slacks
b. IF Business Appointment = Yes & Temp above 70 = Yes
THEN Decision = wear shorts
c. IF Temp above 70 = No
THEN Decision = wear shorts
Business
Appoint-
ment?
Temp
above
70?
No
Yes
Decision =
wear jeans
No
Yes
Decision =
wear slacks
Decision =
wear shorts
Discover more from:
Data Mining
Assiut University
91 Documents





More from:Data Mining
More from:
Data Mining
Assiut University
91 Documents


- More from:Data MiningAssiut University91 Documents