
- Information
- AI Chat
Bioinformatics - summary for bioinformatic
summary for bioinformatic
Course
Bioinformatics (BT_204)
Academic year: 2021/2022
Uploaded by:

0followers
19Uploads
2upvotes
Students also viewed
Related documents
- Genetic engineering Follow 5
- Genetic engineering 2 - summary from Gene Cloning and manipulation Second Edition
- Genetic engineering 5 - summary from Gene Cloning and manipulation Second Edition
- Genetic engineering 3 - summary from Gene Cloning and manipulation Second Edition
- Evolution
- DNA Genetic Markers and Fish biotechnology
Preview text
Bioinformatics
Lab.
• Bioinformatics used for prediction, modelling, and design
• Bioinformatics in Agricultural Biotechnology help at genome analysis, analysis of genome
sequenced data, Identification of sequenced gene, gene expression pattern, and collection
of databases helps in genome mapping
• Computer programs used for determining gene and protein functions establishing
evolutionary relationships and predicting the three-dimensional shapes of proteins
Term Definition
Bioinformatics Subdiscipline of biology and computer science
Biological database
Large, organized body of determined data, usually associated with
computerized software designed to update, query, and retrieve components of
the data stored within the system.
Simple database
Single file containing many records, each of which includes the same set of
information.
Primary database
Consists of data derived directly from experiments such as sequences of
nucleotides or proteins and 3 D structures of a protein/DNA. داتا خااام من المعمل و
مفيهاش اي معلومه مفيدة او تحليل منطقي حتي
Secondary database
Includes primary database analysis results in other important data in the form of
conserved sequences, signature sequences, secondary structures, active site
residues of proteins. باخد الداتا الخام اعالجها علشان اعرف بتتكون من ايه و الخصائص و بناء
عليه اعرف اوظفها بعد كده
Classification of Databases
Based on Data
Types
Database
Based on Type
→
Sequence
Sequence databases contain both nucleic acid
like: GeneBank, EMBL, DDBJ and protein
sequences like: UniProt, and Protein
Information Resource (PIR)
SwissProt → provides a high
level of integration with other
databases and also has a very
low level of redundancy
EMBL → comprehensive
database of DNA and RNA
sequences collected from the
scientific literature and patent
applications and directly
submitted from researchers
and sequencing groups.
GenBank → one of the
fastest growing sources of
known genetic sequences.
Based on Data
Source
Structure
PDB (Protein Data), MMDB (Molecular
Modeling), VAST (Vector Alignment Search),
CDD (Conserved Domain), and NDB
(Nucleic acid Structure)
Based on
Database
Design
Enzyme
Cover wide range of properties and functions,
such as structure, occurrence, kinetics of
enzyme catalyzed reactions, and metabolic
function like: ExPASy, BRENDA, REBASE,
EC enzyme database
Composite
Database
Literature
Provide us library for science work done all
over the world like: MEDLINE, CiteXplore,
OMIM, Patent abstracts, and FlyBase archives
Pathway
Figure out molecular interactions and
chemical reaction networks like: BioCyc,
KEGG pathway, MANET, Reactome
(Laboratory of Cold Spring Harbor, EBI,
Gene Ontology Consortium)
Notes:
- BioCyc database collection comprising EcoCyc and MetaCyc
- Primary databases include: GenBank, DDBJ, EMBL, PIR, PDB, NDB, UniProt, TrEMBL,
and SWISS PROT
- Secondary databases include: PROSITE, Pfam, Blocks, Prints, SCOP, CATH, and KEGG,
InterPro, NRDB, OWL, and RefSeq
Lab & 3
Term Definition
CodonCode
Aligner
An easy-to-use program for Sequence assembly, contig editing, and mutation
detection
FASTA
Format
Is a text-based format for representing either nucleotide sequences or peptide
sequences, in which base pairs or amino acids are represented using single letter
codes. The file begins with a single line description, followed by lines of sequence
data.
Expect (E)
Value
The number of alignments expected by chance with a particular score or better.
default sorting metric and normally gives the same sorting order as Max Score.
Maximum
(Max) Score
The highest alignment score of a set of aligned segments from the same subject
(database) sequence. This normally gives the same sorting order as the E Value.
Maximum
(Max) Identity
The highest percent identity for a set of aligned segments to the same subject
sequence.
CodonCode Aligner feature:
1. Multiple sequence assembly and sequence alignment algorithms
2. Manual and automated sequence editing
3. Align contigs to each other’s
4. Chromatogram editing
5. Starting BLAST searching
6. Detection of heterozygous single nucleotide polymorphism analysis
7. Generate phylogenetic trees and restriction maps
Adding single file from open while adding several files from import
The new added files will be in the “Unassembled Samples” folder
Sample name → left bottom
Number of bases → middle
Quality of the base → right bottom
Similarity Searching on the Databanks → Basic Local Alignment Search Tool (BLAST)
The tree produced from the cladistic methods → cladogram
The tree produced from the phenetic methods → dendrogram
At NJ → the algorithm requires knowledge of the distance between each pair of taxa
The most parsimonious tree → the one with the fewest evolutionary changes
The tree with the maximum likelihood → the most probable tree
At distance matrix:
- All base changes can be considered equally of the possible replacements
- Insertions and deletions are given a larger weight than replacements
- Insertions or deletions of multiple bases at one position are given less weight than
multiple independent insertions or deletions
- Possible to correct for multiple substitutions at a single site
Dendrogram VS. Cladogram structures
Steps for Phenetic method:
1. Make alignment
2. Create distance matrix
3. Calculate the phylogenetic tree with one of the clustering algorithms: UPGMA clustering
or Neighbor joining
UPGMA clustering = Unweighted Pair Group Method using Arithmetic averages
Steps followed by UPGMA:
- Assume that initially each species is a cluster on its own
- Join closest 2 clusters and recalculate distance of the joint pair by taking the average
- Repeat this process until all species are connected in a single cluster
Cladogram
Branch
Branch
Steps of phylogenetic analysis:
1. Choose the organism or gene family
2. Alignment → sequencing → assembly
3. Alignment
4. Evolutionary model
5. Phylogenetic analysis
6. Tree construction
7. Evaluation
Was this document helpful?
Bioinformatics - summary for bioinformatic
Course: Bioinformatics (BT_204)
University: October University for Modern Sciences and Arts
Was this document helpful?

Bioinformatics
Lab.1
• Bioinformatics used for prediction, modelling, and design
• Bioinformatics in Agricultural Biotechnology help at genome analysis, analysis of genome
sequenced data, Identification of sequenced gene, gene expression pattern, and collection
of databases helps in genome mapping
• Computer programs used for determining gene and protein functions establishing
evolutionary relationships and predicting the three-dimensional shapes of proteins
Term
Definition
Bioinformatics
Subdiscipline of biology and computer science
Biological database
Large, organized body of determined data, usually associated with
computerized software designed to update, query, and retrieve components of
the data stored within the system.
Simple database
Single file containing many records, each of which includes the same set of
information.
Primary database
Consists of data derived directly from experiments such as sequences of
nucleotides or proteins and 3 D structures of a protein/DNA. و لمعملا نم ماااخ اتاد
يتح يقطنم ليلحت وا ةديفم همولعم يا شاهيفم
Secondary database
Includes primary database analysis results in other important data in the form of
conserved sequences, signature sequences, secondary structures, active site
residues of proteins. ءانب و صئاصخلا و هيا نم نوكتتب فرعا ناشلع اهجلاعا ماخلا اتادلا دخاب
هدك دعب اهفظوا فرعا هيلع
Classification of Databases
Based on Data
Types
Database
Based on Type
→
Sequence
Sequence databases contain both nucleic acid
like: GeneBank, EMBL, DDBJ and protein
sequences like: UniProt, and Protein
Information Resource (PIR)
SwissProt → provides a high
level of integration with other
databases and also has a very
low level of redundancy
EMBL → comprehensive
database of DNA and RNA
sequences collected from the
scientific literature and patent
applications and directly
submitted from researchers
and sequencing groups.
GenBank → one of the
fastest growing sources of
known genetic sequences.
Based on Data
Source
Structure
PDB (Protein Data), MMDB (Molecular
Modeling), VAST (Vector Alignment Search),
CDD (Conserved Domain), and NDB
(Nucleic acid Structure)
Based on
Database
Design
Enzyme
Cover wide range of properties and functions,
such as structure, occurrence, kinetics of
enzyme catalyzed reactions, and metabolic
function like: ExPASy, BRENDA, REBASE,
EC enzyme database
Composite
Database
Literature
Provide us library for science work done all
over the world like: MEDLINE, CiteXplore,
OMIM, Patent abstracts, and FlyBase archives
Pathway
Figure out molecular interactions and
chemical reaction networks like: BioCyc,
KEGG pathway, MANET, Reactome
(Laboratory of Cold Spring Harbor, EBI,
Gene Ontology Consortium)





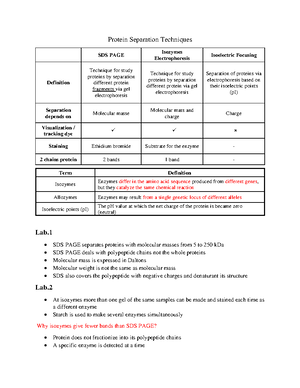
Students also viewed
Related documents
- Genetic engineering Follow 5
- Genetic engineering 2 - summary from Gene Cloning and manipulation Second Edition
- Genetic engineering 5 - summary from Gene Cloning and manipulation Second Edition
- Genetic engineering 3 - summary from Gene Cloning and manipulation Second Edition
- Evolution
- DNA Genetic Markers and Fish biotechnology